mastodonのRedisをAWS ElasticCacheからdockerへ変更
Ariesです。 私のMastodonインスタンス(結局サーバ呼びになったんでしたっけ)の構成を変更しました。
ちなみに私のアカウントはこちら。
環境
- AWSにてホストしています
- EC2 t3.micro Ubuntu 18.04
- nginx
- mastodon (docker)
- RDS PostgreSQL 9.6.8
- ElasticCache Redis (サイズ忘れましたが最小です)
構成
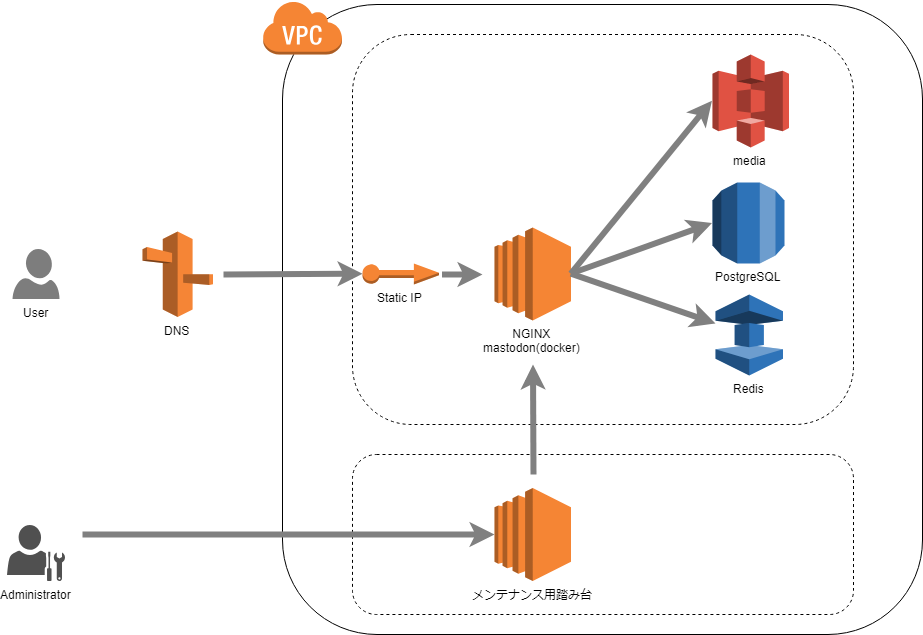
以前の構成
EC2の上に直接インストールしたnginxをリバースプロキシにし、dockerでmastodon本体(web, streaming, sidekiq)をホスト、DBはPostgreSQLもRedisも両方マネージドサービス、という構成でした。
この構成を以下のように変更しました。
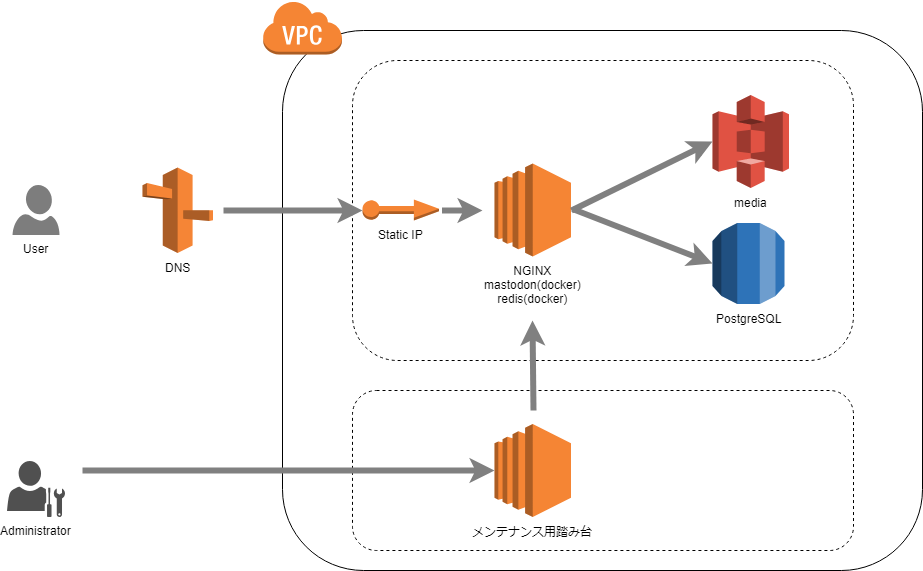
現在の構成
結果として$20ほどの節約になっています。
経緯
MastodonにおいてRedisはタイムラインの作成に使われているそうですが、Redis DBをロストしてしまった時のためのコマンドがmastodonには用意されています。
そのためわざわざお高いマネージドのredisを使う必要は無いと思います。自由が効くお一人様インスタンスだと特にそうかなと。
という話をヒョロワーさんから聞いたため廉価構成に変更しました。
わたしは半年ほど前のインスタンス構築時、Web周りの知識なんぞほぼ無知の状態だったため、大きいガバをやらかしても復旧しやすいようにDBはお金で殴ったというわけです。(その結果としてFGO美遊を宝具2にできず1で我慢するとかAsrock Deskmini A300を買えてないとかは別のお話……)
docker構成の場合タイムライン再構築は
% docker exec -i -t mastodon_web_1 bash
% ./bin/tootctl tootctl feeds build
その後
変更後1日ですが、今のところサーバが止まったりなどはしていません。
正直t3.microだとRAM 1GBでbuildも時間がかかりますし、更に不定期でサーバのCPU使用率が100%近くに張り付いてしまう事象が構成変更前からちょくちょく発生しています。(面倒でまだちゃんと調査しておらず……)
ですので浮いたお金でt3.smallへのスケールアップを行いたいところですが、リザーブドインスタンスで買ってしまっているため変更すると損するというね……。
そんな状況なので、スケールアップの代わりに障害時復旧を自動化しました。
この自動化については後ほどブログ記事を書く予定です。(構成としては、cloudwatchのアラームを受けてlambdaからSSMを動かす、といった形です)
2019/02/09追記 自動復旧スクリプトが動くまでもなくインスタンスに全くアクセスできなくなる状態になり用を名なさないことが判明しました。
そして、今まで死んでいた原因もフォロワーさんの手助けによりわかりました。
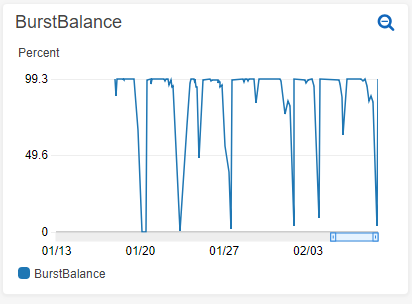
EBS BurstBalance
t2, t3インスタンスにおいてCPUクレジットという概念が存在することは知っていましたが、EBSにも存在していたとは露知らず……。
microだとdocker-composeのbuildが行えないため、swapを設定していたのが問題でした。
現在はそこまで大きな損にはならないことを確認したため、大人しくmicroからsmallへとスケールアップを行い運用しております。